What is Kubernetes (k8s), its high-level architecture and its capabilities ?
Series of hands-on Kubernetes tutorials to make your app highly-available and scalable.




Photo by Ian Taylor on Unsplash
This is the first post in the series of posts related to Kubernetes. This introductory post will talk about what Kubernetes is, why it is used, its high level architecture and what are it's core components and concepts.
Later posts in this series will be more hands-on tutorials that will cover details on the working of Kubernetes, setting up of cluster, scaling deployments, defining services etc.
Kubernetes, Mesos, Dockers are few of the Open-Source projects that has drastically changed the way we deploy and manage our software applications and services. A lot has changed in this DevOps space in last 10 years. If you are interested to know what has changed, checkout one of my earlier blog posts about building and deploying large scale web-apps. Out of these open-source projects, surely Kubernetes and Dockers have taken a lead. Kubernetes in short is also known as k8s (here 8 stands for number of letters between k and s characters in word kubernetes). It started gaining traction among software developers and DevOps community in 2015 when Google made this project open-source.
What is Kubernetes ?
Kubernetes is a distributed software that creates a clustered and scalable workload deployment infrastructure. It allows us to deploy, serve, monitor, load-balance, scale-out, scale-in our containerized applications (workloads) in automated manner on physically (or virtually) distributed cluster of computers (also known as nodes, in cluster terminology).
Let's see how we can use Kubernetes to make our workloads highly available and scalable along with making the deployment process smooth and painless. Below diagram will help us understand the overall architecture of Kubernetes cluster and what are its key components and concepts.
Kubernetes architecture and key components
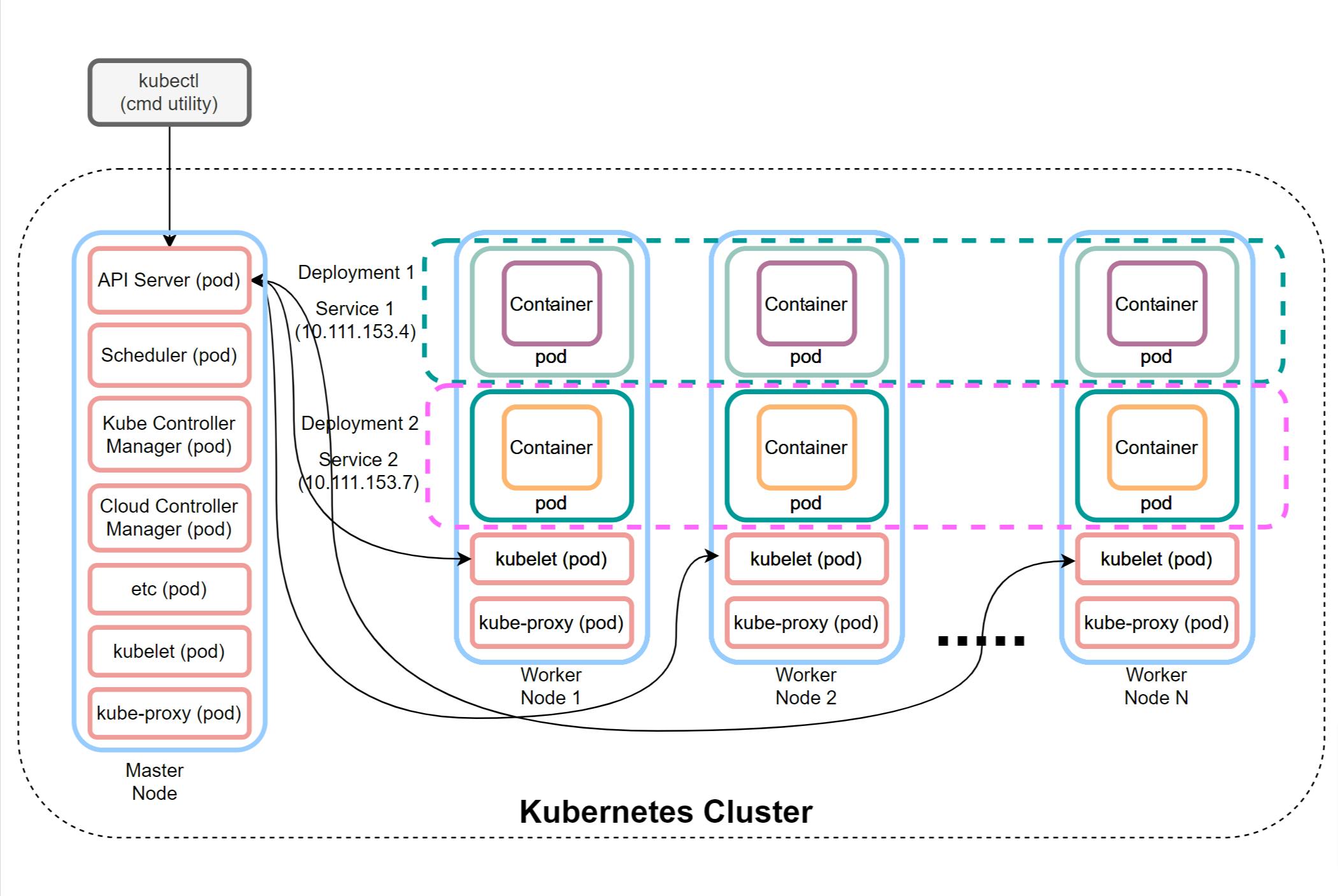
Below, I will briefly cover the main components of Kubernetes and explain their high-level functionality.
Cluster: In general term, cluster means a
group. In computing, cluster means group of computing machines. These machines can be physical (bare metal) or virtual computers that works together as unified single compute resource.Node: By
node, we mean single compute machine in cluster. Again this can be either physical or virtual. In Kubernetes, there are two type ofnodes-- master node and worker nodes. Master node is the computer that runs control plane and deploys, controls, manages, schedules and monitors workloads on worker nodes. Most of the critical Kubernetes system processes run on master node aspod(explained below).Pod : In Kubernetes,
podrepresents the smallest unit of deployment that Kubernetes manages. A pod may have one or more containers running in it along with other shared resources like network namespace and shared volumes for instance. In regular scenarios, most of the pods are created with single container in them. There are some system pods that Kubernetes creates and are critical for its proper functioning. Most of these system pods run on master node, with exceptions ofkubeletandkube-proxythat runs on all Kubernetes nodes (master as well as each worker node). Systempodsthat run on masternodeare as below:kube-apiserver(in general, it is also known as API server) is a system process that runs as apodon master node and is responsible for communicating with worker nodes throughkubeletprocess that runs on each of the worker nodes. API server is like a central nervous system, that is critical for proper working of Kubernetes cluster.API serveralso serves as a server forkubectlcommand line utility through which we can run commands to perform specific operations on cluster.kubectlis the command line utility that works as a client and can be installed on any computer outside cluster, to manage the cluster. Throughkubectlwe can perform any kind of cluster operations like creating, listing and deleting different cluster objects, for instancepod,deployment,serviceetc.kube-scheduleris a system process that runs as apodon master node and is responsible for scheduling workloads (application pods) on worker nodes. It is aware of available resources on healthynodesand also maintains priority queue forpodsto be scheduled. It determines whichpodshould be deployed on whichnode. It can also preempt, evict and movepodsacrossnodeson need basis to optimize the resource utilization within cluster nodes.kube-controller-manageris a system process that runs as apodon master node and is responsible to keep a watch on the state of cluster. It ensures that cluster's current state always remain as close to desired state. Whenever there is a change in state that deflects cluster from its desired state, controller manager takes action through other system pods to bring back the cluster state to desired state. For instance if we want 5 instances of an application to be running (desired state) and somehow controller manager notes that there are only three instances running, it will ensure that two more instance (pods) spin up to bring back to desired state.Kubernetes supports multiple cloud providers and allows us to run Kubernetes cluster in any cloud environment. Cloud controller manager is a system process that runs as a
podon master node and responsible to isolate and decouple the cloud complexities from Kubernetes. For instance if we want to add some new nodes in cluster that are hosted in cloud, the cloud controller manager takes care of procuring those nodes using cloud APIs. Cloud controller manager follows the plugin architecture that allows different cloud providers to add different capabilities to support Kubernetes on their respective cloud platforms.etcis a system process that runs as apodon master node. It manages the storage for cluster as a key-value store. You can read more details aboutetcdhere.kubeletis a system process that runs as apodon each of the cluster node. It acts as an agent on behalf of API server that manages and monitorspodson that worker node. It ensure it follows the commands (in terms of podspecs) from API server to maintain the assigned pods on worker node. It is also responsible for registering a new node in Kubernetes cluster.kube-proxyis a system process that runs as apodon each of the cluster node. Its works as a network proxy. It maintains network rules on nodes. These network rules allow network communication topodsfrom network sessions inside or outside of the Kubernetes cluster.
Container: Kubernetes is built on an idea of containers. Container is an encapsulated package that holds the workload (application) and all its dependencies within it to make the application completely portable from deployment perspective. It means, if you package your application as container then you can deploy and run your application on either Windows, Linux or Mac machines, provided those machines have container runtime software installed which can run the containers.
Dockeris one such example of container runtime engine and it is the default container runtime engine for Kubernetes. If you are new to containers, I would request you to go through this quick video, that talks about differences between Container and VM.Deployment: Term
deploymentin Kubernetes means, a logical grouping ofpodsrunning the same application / workload in their containers (ReplicaSet). These pods need not to be on the samenode. They can be distributed anywhere on cluster nodes. Point of creating a logical grouping likedeploymentis to easily scale-out or scale-in the workload across nodes. To give a sense to it, let me give you a practical scenario. Let's consider a simple app that manages customers and their orders. If we build this app considering Domain Driven Design principles, we will have two bounded contexts - one for customers and another for orders. In microservices context, these will be the two separate services with their own DBs. Now with this example think of a use-case where number of orders suddenly peaks during festival season. To handle that use-case, we need to scale-out our order service but may not do the same for our customer service. This particular need to scale specific service (in general workload) is addressed bydeploymentin Kubernetes. In later tutorials of this series, we will see how it is done with hands-on example.Service: In Kubernetes
serviceis a concept to logically binding similarpodsand assign them a common network identity (network name and network IP). Although the name are same, but do not confuse Kubernetesservicewith amicroservicein software development. It may represent an actualmicroserviceor it may even represent a scalable monolithic app (depends upon how you design your app) running as workload. Purpose of definingservicein Kubernetes is to expose the pods running workload as a unified resource to other internal (within cluster) or external consumers of workload. Asserviceassigns a virtual network IP and network name to set ofpods, this allows access to the workload running in those pods using virtual IP or network name of theservice, eliminating the need to know the IP or the name of the individual pods to access them (which anyway is not possible from outside the cluster). It also allows us to load balance the traffic across pods running the workload.
That is it all about the purpose and higher level architecture of Kubernetes. I hope this post helped you understand what Kubernetes is and its overall high-level architecture with the functioning of its each of the key components. In next post I will cover how to setup a single node cluster on your local machine using minikube. Stay tuned.